Note
Go to the end to download the full example code.
Two Moons Classification¶
This example demonstrates how to use the Neuralk Seldon model on the
classic two moons dataset - a simple binary classification task with a
non-linear decision boundary.
Note
For this example to run, the environment variable API_KEY must be set
with your Neuralk API key.
Generate the two moons dataset¶
We use the neuralk.datasets module to generate the two moons data.
import os
import matplotlib.pyplot as plt
import numpy as np
import polars as pl
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from neuralk import Seldon
from neuralk.datasets import two_moons
# Load the two moons dataset
moons_data = two_moons()
df = pl.read_csv(moons_data["path"])
X = df.drop("label").to_numpy().astype(np.float32)
y = df["label"].to_numpy()
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"{X_train.shape=} {y_train.shape=} {X_test.shape=} {y_test.shape=}")
X_train.shape=(400, 2) y_train.shape=(400,) X_test.shape=(100, 2) y_test.shape=(100,)
Fit and predict with the Neuralk Seldon model¶
Seldon uses Neuralk’s In-Context Learning model. Note that no long-running training is happening - the model is pretrained and uses the training data as context for predictions.
model = Seldon(api_key=os.environ["API_KEY"])
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.3f}")
# Check API response details
print(f"Credits consumed: {model.credits_consumed}")
print(f"Latency: {model.latency_ms}ms")
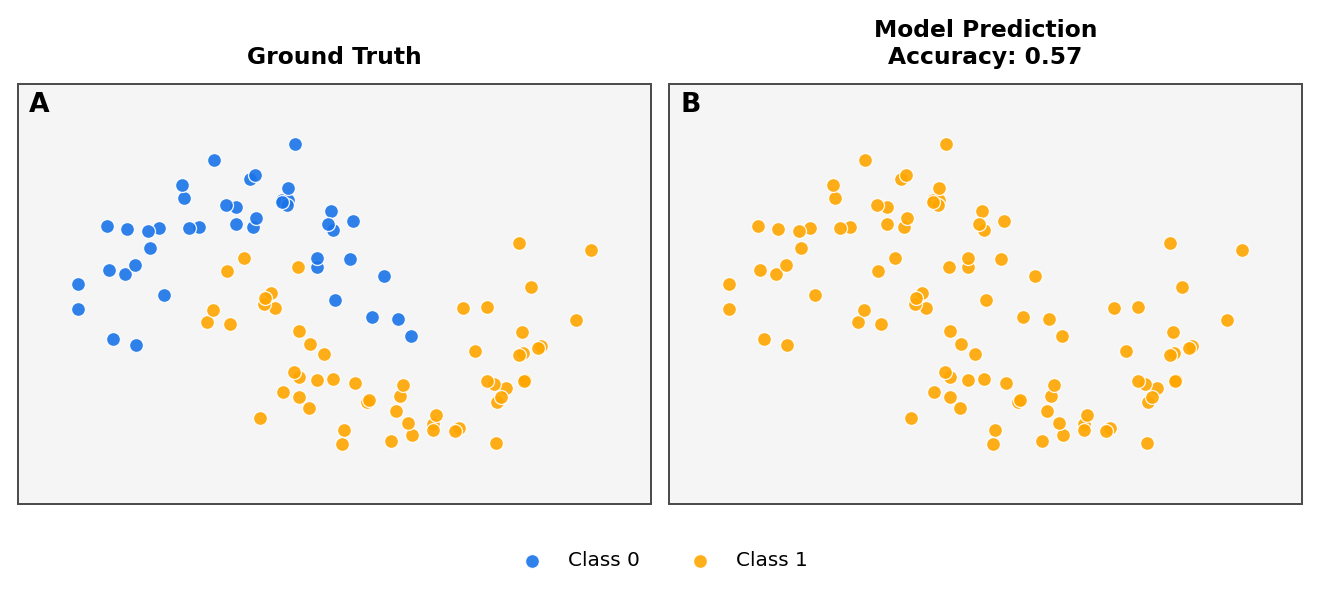
Accuracy: 0.970
Credits consumed: 1
Latency: 354ms
Visualize the results¶
We plot the ground truth labels alongside the model predictions.
plt.rcParams.update(
{
"axes.edgecolor": "#4d4d4d",
"axes.linewidth": 1.2,
"axes.facecolor": "#f5f5f5",
"figure.facecolor": "white",
}
)
fig, axes = plt.subplots(1, 2, figsize=(11, 5), dpi=120)
titles = ["Ground Truth", f"Model Prediction\nAccuracy: {acc:.2f}"]
colors = ["#1a73e8", "#ffa600"] # Blue & orange
for idx, ax in enumerate(axes):
labels = y_test if idx == 0 else y_pred
for lab in np.unique(labels):
ax.scatter(
X_test[labels == lab, 0],
X_test[labels == lab, 1],
s=70,
marker="o",
c=colors[int(lab)],
edgecolors="white",
linewidths=0.8,
alpha=0.9,
label=f"Class {lab}" if idx == 0 else None,
zorder=3,
)
ax.set_xticks([])
ax.set_yticks([])
ax.set_aspect("equal")
ax.set_title(titles[idx], fontsize=14, weight="bold", pad=12)
ax.grid(False)
x_margin = 0.4
y_margin = 0.4
ax.set_xlim(X_test[:, 0].min() - x_margin, X_test[:, 0].max() + x_margin)
ax.set_ylim(X_test[:, 1].min() - y_margin, X_test[:, 1].max() + y_margin)
ax.text(
0.05,
0.98,
chr(ord("A") + idx),
transform=ax.transAxes,
fontsize=16,
fontweight="bold",
va="top",
ha="right",
)
handles, labels_ = axes[0].get_legend_handles_labels()
fig.legend(
handles,
labels_,
loc="lower center",
ncol=2,
frameon=False,
fontsize=12,
bbox_to_anchor=(0.5, 0.02),
)
fig.tight_layout()
plt.subplots_adjust(bottom=0.05)
plt.show()
Total running time of the script: (0 minutes 1.011 seconds)